
Neuronové sítě dnes hýbou světem technologií – od rozpoznávání obrázků po generování textů. Aby ale dobře fungovaly, je potřeba je správně navrhnout a otestovat. Samuel Mintál, absolvent informatiky na Matfyzu, se ve své diplomové práci zaměřil na chytré zkratky – metody, které dokážou rychle odhadnout, jak dobrá síť bude, aniž by bylo nutné ji složitě trénovat. Výsledkem jeho výzkumu je nový přístup, který může ušetřit spoustu času i výpočetního výkonu.
Mohl byste stručně představit svou práci?
Architektúra neurónovej siete definuje, akým spôsobom sú jej neuróny navzájom prepojené. Tým pádom má vplyv na výslednú výkonnosť siete, a teda je, vrátane množstva iných faktorov, taktiež optimalizovaná. Za účelom vybrania najlepšej architektúry ich výkon musíme vedieť ohodnotiť. Typické plné natrénovanie neurónových sietí potrebné za účelom ich testovania je ale príliš pomalé.
Výskum v tejto oblasti sa teda sústredil na vývoj menej dôkladných proxy, ktoré výkon siete dokážu odhadnúť bez ich plného natrénovania, a teda o dosť rýchlejšie, i keď za cenu nižšej presnosti. Presne týmto metódam som sa v práci venoval. Výsledok práce bol nový koncept a implementácia proxy, ktorá kombinuje existujúce typy proxy takým spôsobom, ktorým sa eliminujú ich inherentné nevýhody. Ilustráciu tohto konceptu môžeme vidieť na obrázku nižšie.
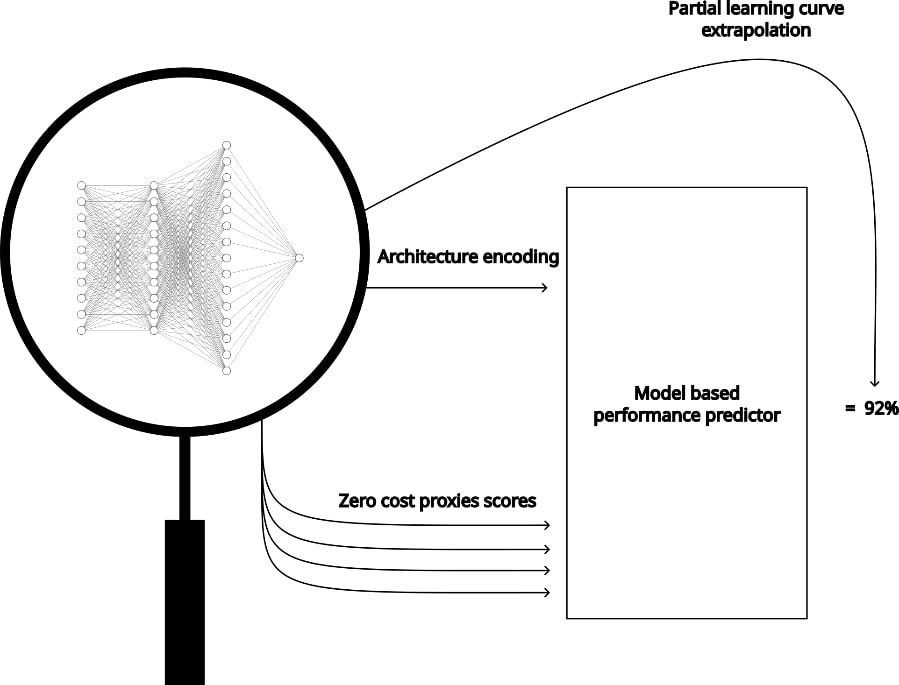
Co vás inspirovalo k tomu, abyste se zaměřil právě na toto téma?
Celé to začalo záujmom písania práce pod konkrétnym vedúcim, pánom Romanom Nerudom, ktorého predmety ma počas štúdia bavili, a zároveň viedol práce v oblasti, ktorá ma zaujímala. Pôvodne mi bolo navrhnuté spracovať oblasť menej dôkladných proxy iným spôsobom. V priebehu rešerše som ale zistil, že nami pôvodne zamýšľaná téma už bola spracovaná, a teda ju bolo treba zmeniť. Na základe prečítanej literatúry z oblasti mi ale napadla kombinácia proxy, ktorá by literatúrou spomínané problémy jednotlivých proxy mohla eliminovať. Tento nápad sme s vedúcim prediskutovali a výsledná téma bola na svete.
Jaký konkrétní přínos nebo využití má vaše práce?
Výsledkom práce je koncept proxy a aj jeho konkrétna implementácia, ktorá umožňuje rýchlejšie ohodnocovanie výkonnosti architektúr. V rámci výskumu sa jedná o novú vec, ktorá sa dá určite preskúmať do väčšej hĺbky. Keďže naša proxy sa skladá z troch na sebe nezávislých, menej dôkladných proxy, je napríklad možné oproti sebe porovnať rôzne konfigurácie, pričom ideálna z nich sa môže skrz vývoj v konkrétnych oblastiach meniť.
S jakými technologiemi jste pracoval a jaké metody jste využíval?
Ako väčšina aplikácií v oblasti strojového učenia, aj moja bola písaná v Pythone. Od toho sa odvíjal aj výber použitých knižníc, ktoré na základe mojich skúseností v praxi sú taký industry standard. Čo sa týka všeobecných knižníc, použil som najmä pandas, numpy a matplotlib. Na druhú stranu, knižnice špecifické pre oblasť strojového učenia boli scikit-learn a oba tensorflow aj pytorch, pričom pytorch využíval jedine kód, ktorého implementácie vybratých proxy som využíval.
Co bylo během psaní vaší práce nejtěžší? Je něco, co byste zpětně udělal jinak?
Najťažšie na práci boli sekcie zaoberajúce sa špeciálnym poddruhom menej dôkladných proxy, preložiteľné ako proxy s nulovými nákladmi. Ich charakteristickou vlastnosťou je, že výkon siete odhadnú v rámci iba pár sekúnd, a to bez potreby pre predchádzajúcu inicializáciu.
Najjednoduchším príkladom takejto proxy je taká, ktorej skóre pridelené neurónovej siete priamo odpovedá jej veľkosti, pričom intuícia na pozadí tohto je tá, že väčšia sieť by mala byť šikovnejšia. Typicky sú ale po matematickej stránke náročné na pochopenie, či implementáciu. Taktiež nimi sa zaoberajúca literatúra je limitovanejšia, keďže sa jedná o oblasť starú len pár rokov.
Práve snahou o vlastnú implementáciu existujúcich proxy s nulovými nákladmi som strávil najviac času, ktorý vyšiel navnivoč. Riešenie nakoniec bolo použiť už existujúci kód, ktorý bol vydaný k jednému článku, z ktorého som čerpal. Práve toto je kód využívajúci pytorch, ktorý v odpovedi vyššie spomínam. Písať teda prácu znova, použil by som už existujúcu implementáciu hneď zozačiatku.
Jakým způsobem jste ověřoval výsledky své práce?
Ako sme si už vraveli, úlohou menej dôkladných proxy je vedieť správne ohodnotiť, čiže aj zoradiť, architektúry nenatrénovaných neurónových sietí podľa ich výkonnosti. Aby sme teda dokázali férovo porovnávať rôzne proxy, tak architektúry neurónových sietí, ktorých výkonnosť odhadujú, by mali byť identické. Zároveň, aby sme vedeli, aké je vlastne správne zoradenie daných sietí podľa ich výkonnosti, tak ich musíme všetky plne natrénovať a otestovať. Toto je ale veľmi zdĺhavý proces. Oba tieto problémy riešia takzvané NAS benchmarks, a to tým, že poskytujú konkrétnu množinu architektúr neurónových sietí, pre ktoré zároveň zahŕňajú ich výsledný výkon a rôzne iné dáta. NAS benchmark, ktorý som v práci použil, sa volá NAS-Bench-201.
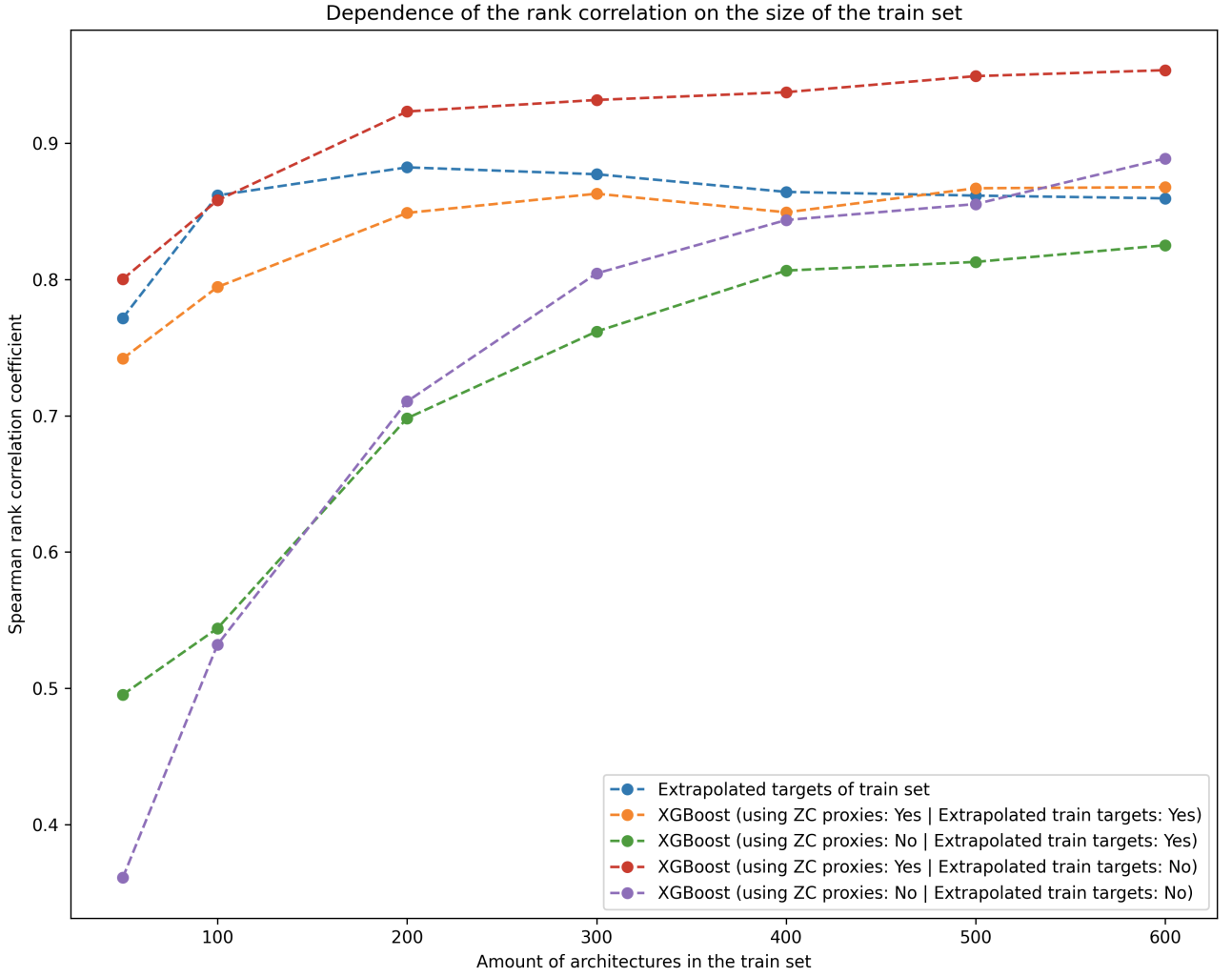
Samotné experimenty v závere práce následne merali ako správne naša proxy zoraďovala množinu testovacích architektúr neurónových sietí z NAS-Bench-201 (pomocou Spearmanovho koeficientu korelácie, pričom vyšší je lepší) vzhľadom k veľkosti trénovacej množiny danej proxy (menšia je lepšia). Navyše, keďže v našom prípade veľkosť trénovacej množiny priamo odpovedá času potrebnému pre proxy k nadobudnutiu nameranej výkonnosti, tak môžeme porovnávať aj nimi potrebný čas.
Na grafe nižšie, ktorý sa nachádza v záveru práce, môžeme vidieť porovnanie viacerých proxy, pričom my sa teraz budeme sústrediť na dve z nich. Prvá z nich je nami navrhnutá proxy, ktorú reprezentuje oranžová krivka. Druhou z nich je proxy odpovedajúca naivnému využitiu proxy, na ktorej náš prístup zakladáme. Tú reprezentujeme fialovou krivkou.
Vidíme, že naivný prístup prekoná ten náš až pri veľkosti trénovacej množiny o 600 architektúrach. Kľúčové tu je ale brať v úvahu to, že naivný prístup v tomto prípade o 600 trénovacích architektúrach potrebuje až okolo 28 dní, než dosiahne daný výkon, pričom náš prístup sa k slabšiemu, no veľmi porovnateľnému výkonu dostane s trénovacou množinou o 300 sieťach, na ktoré potrebuje menej než jeden a pol dňa (tieto časy sú odhadované za predpokladu, že všetky proxy bežia len na jednom počítači s relatívne výkonným GPU).
Co považujete za nejdůležitější výsledek nebo závěr své práce?
Práca má viacero výsledkov, no za najdôležitejší z nich považujem predstavený koncept proxy. Experimenty na našej implementácii ukázali dobrý výkon, ktorý sme opodstatnili aj na teoretickej úrovni. Zároveň sme nepreskúšali úplne všetky možné konfigurácie, takže nie je vylúčené, že nejaký výkon stále nechávame na stole.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Vypracovaním zadania vznikli nejaké otázky, ktoré sme v nej nezodpovedali, či nerozvinuli do väčšej hĺbky, pričom ich komplexitou sa držia na úrovni práce. Viem si teda predstaviť, že by sa na prácu dalo naviazať z pohľadu ďalšej študentskej práce, či zároveň vedeckej komunity, keďže sa jedná o aktuálnu tému.
Jaké máte plány do budoucna?
V rámci môjho kariérneho smeru, ktorým som sa vybral, sa stretávam s ML modelmi, a najmä s neurónovými sieťami, celkom pravidelne. Verím teda, že znalosti nadobudnuté napísaním práce dokážem skôr či neskôr na správnom projekte využiť.



