
„Plánování výroby je velmi zajímavé téma, u kterého se dá dobře propojit teorie s praxí,“ říká Lukáš Nedbálek, student magisterského programu Informatika – Umělá inteligence na Matfyzu, který ve své bakalářské práci analyzoval pomocí výpočetních metod slabá místa výroby.
Mohl byste stručně představit svou práci?
Plánování je klíčový proces (nejen) v průmyslu. Úkolem je v čase rozdělit zdroje (stroje, zaměstnance, materiály) na výrobu jednotlivých zakázek. Hledaný plán výroby (také rozvrh) musí splňovat různé omezující podmínky – constraints – a zároveň hledáme nejlepší plán vzhledem k nějakým (optimalizačním) kritériím (například čas dokončení zakázek či zpoždění vůči dodacím lhůtám).
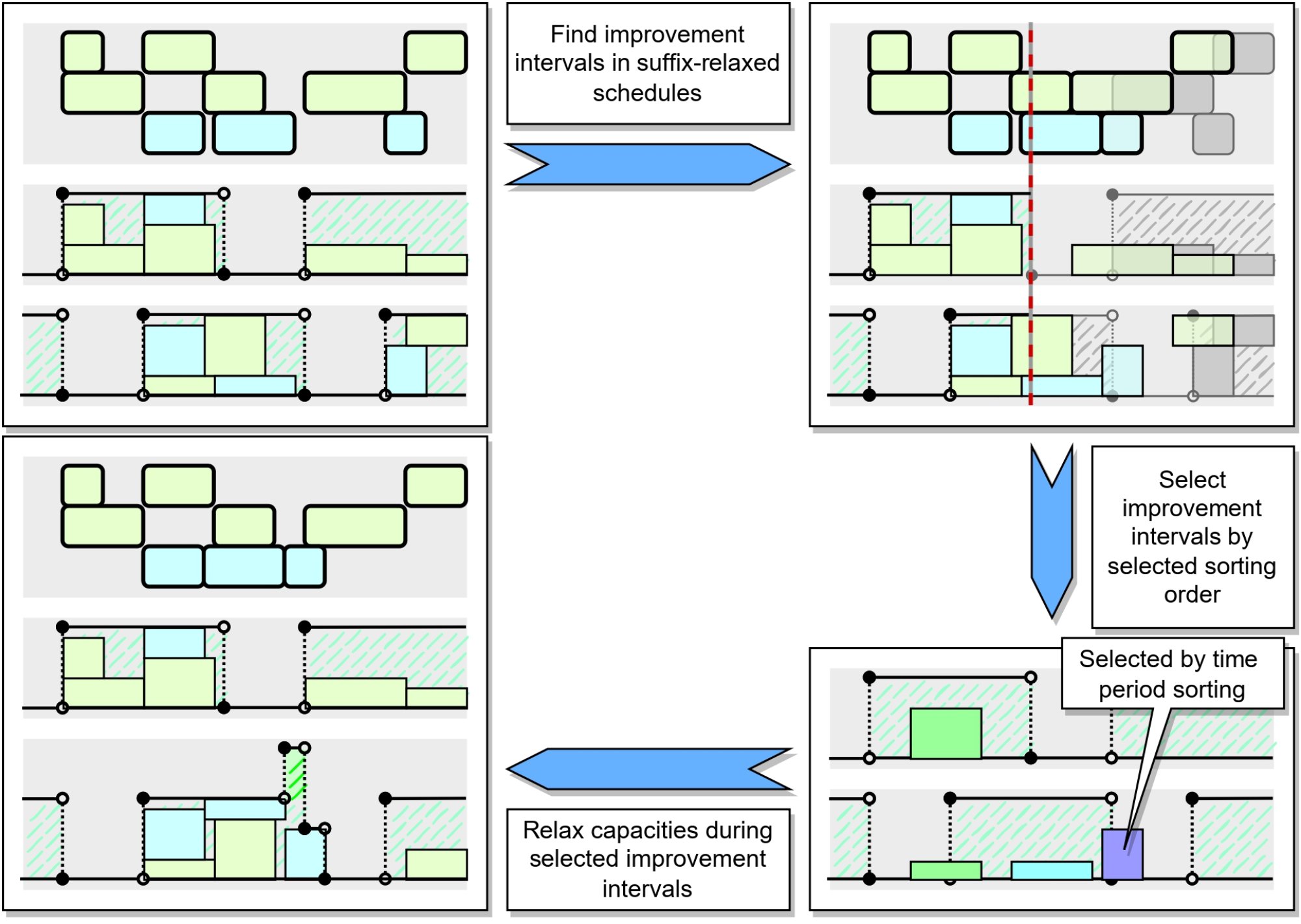
Cílem práce bylo v plánu výroby hledat „slabá místa“ – bottlenecky – kvůli kterým nemůžeme získat lepší plán vzhledem k času dokončení nějaké vybrané zakázky. Pro identifikované bottlenecky částečně uvolníme související kapacitní podmínky a zkoumáme, jaké zlepšení získáváme.
V praxi se jedná o situaci, kde například v nějaké továrně již máme naplánovanou výrobu a z různých důvodů bychom si přáli, aby nějaká specifická zakázka byla dokončena dříve než při dodržení současného plánu. Můžeme pak hledat, kde přidat novou směnu nebo kde některým zaměstnancům směnu prodloužit, abychom zvýšili procesní kapacity, a tím umožnili dřívější zpracování potřebných zakázek.
Co vás inspirovalo k tomu, abyste se zaměřil právě na toto téma?
Ve svém současném zaměstnání se věnuji vývoji plánovacího softwaru pro průmyslové firmy. K tématu průmyslové výroby a souvisejícím informatickým problémům mám tak velmi blízko. Zároveň jsem se skrze zaměstnání seznámil i se svým vedoucím – který se problematice věnuje na teoretické úrovni – a záhy jsme se začali tématu věnovat.
Můžete vysvětlit, jaký konkrétní přínos nebo využití má vaše práce?
Věnovali jsme se rozvrhování projektů s omezenými kapacitami, kde se doposud současný výzkum identifikací bottlenecků a navrhováním změn v rozvrhu nezabýval. Adaptovali jsme existující přístupy z příbuzných problémů a ukázali, že jsou aplikovatelné i v námi zkoumaném problému. Také jsme navrhli nový přístup pro řešení tohoto problému, využívající jeho různých specifických vlastností. Práce představuje první pokus o řešení dané úlohy na daném problému. Budoucí výzkum by mohl navázat na tomto poli rozšiřováním a zdokonalováním našich metod nebo návrhem metod nových. Doufáme, že naše výsledky poslouží jako proof of concept pro řešení naší úlohy.
S jakými technologiemi jste pracoval a jaké metody jste využíval?
Projekt je psaný v Pythonu, využívá různé již tradiční knihovny (numpy, matplotlib, networkx). K častému hledání plánů výroby se využívá constraint programming, konkrétně skrze komerční nástroj ILOG Constraint-Programming Optimizer od IBM. (Používá se však stejně jako podobné constraint programming nástroje – mnoho z nich je volně dostupných.)
Co pro vás bylo během psaní práce nejtěžší? Je něco, co byste zpětně udělal jinak?
Často jsme přišli s nějakou myšlenkou či nápadem na řešení, ale bylo složité je implementovat. K realizaci našich metod jsme využívali netradičních modifikací klasických přístupů, a tak bylo potřeba dlouze promýšlet všemožné detaily zavádění takových modifikací.
Zpočátku jsem například zamýšlel jiný přístup k řešení – modelování jako optimalizační problém. Protože jsem však tou dobou neměl v tomto směru mnoho zkušeností, vydali jsme se směrem jiným. Nyní si myslím, že takových zkušeností mám více, a věřím, že by stálo za to původní směr znovu zkusit.
Jakým způsobem jste ověřoval výsledky své práce?
Prováděli jsme experimenty, které testovaly dvě naše navržené metody. Protože se zatím ještě žádný výzkum tímto směrem neorientoval, srovnávaly jsme pouze naše metody mezi sebou. Výsledkem bylo, že oba odlišné přístupy jsou použitelné na řešení dané úlohy. Překvapivě metoda, kterou jsme zpočátku považovali za slabší, se pro určité problémy ukázala být silnější než metoda druhá, kterou jsme prvotně považovali za lepší pro danou úlohu.
Pro naši úlohu jsme nenašli vhodný dataset – využili jsme instance příbuzného problému z datasetu PSPLIB. Tyto instance jsme dále obohacovali, aby přesně modelovaly náš problém.
Co považujete za nejdůležitější výsledek nebo závěr své práce?
Ukázali jsme, že metody standardně vyžívané na příbuzné problémy se dají využít i na námi studovaný problém. Vyzkoušeli jsme několik přístupů – některé adaptované právě z příbuzných problémů, některé nově navržené. Každý z nich se dá dále rozšířit či se jím inspirovat, ať už při řešení stejného problému, tak i jako prostředek k řešení problémů příbuzných.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Věřím, že pro odborníky v oboru plánování by mohla práce ukázat, že námi řešený problém se dá řešit metodami známými z jiných problémů a že v tomto směru je stále na čem pracovat a čemu se věnovat.
Plánování výroby je velmi zajímavé téma, hlavně díky praktickému využití. Osobně jej vnímám jako pěknou kombinaci teoretického zkoumání a řešení praktických problémů. Pro další studenty věřím, že plánování, a umělá inteligence obecně, nabízí bohatou škálu zajímavých problémů, od ryze teoretických po značně praktické, a že se dá pracovat na zajímavém tématu, kde se teorie setkává s praxí.
Jaké máte plány do budoucna?
Téma momentálně zpracováváme do odborného článku. Nevylučuji, že se tématu budu věnovat i nadále – vidíme mnoho míst, kde lze navázat, kde zlepšovat, kde vymyslet něco nového. Zároveň však v oblasti plánování a umělé inteligence existuje mnoho jiných problémů, které jsou neméně zajímavé a stálo by za to se jim věnovat. Zatím tedy nevím, zda budu pokračovat v daném tématu, anebo mě zaujme něco nového, rozhodně se však budu dál věnovat umělé inteligenci, která mě baví.
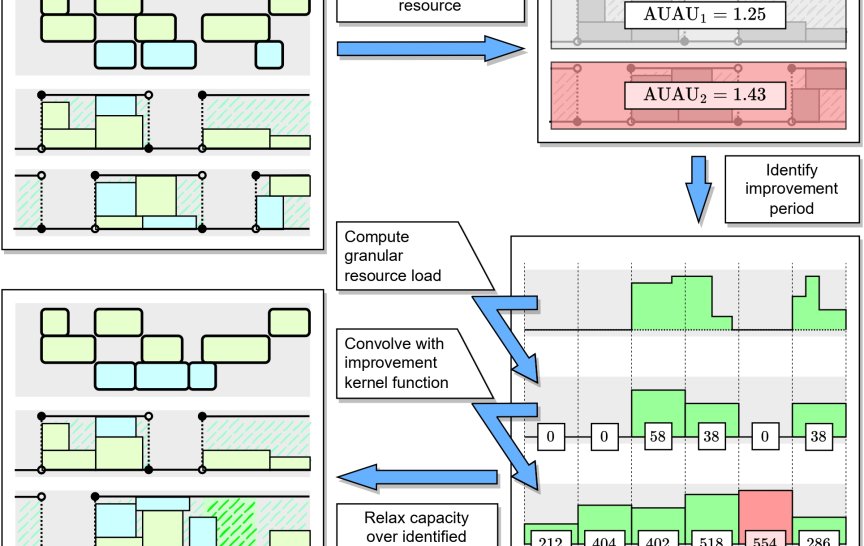
 Animace výše
popsaného procesu: Na počátku obdržím rozvrh výroby, rozhodnu se pro
zlepšení času dokončení určité operace a identifikuji bottleneck zdroj,
který brání v dřívějším dokončení vybrané operace. V určeném úseku
pak navýším kapacity daného zdroje a získám nový rozvrh.
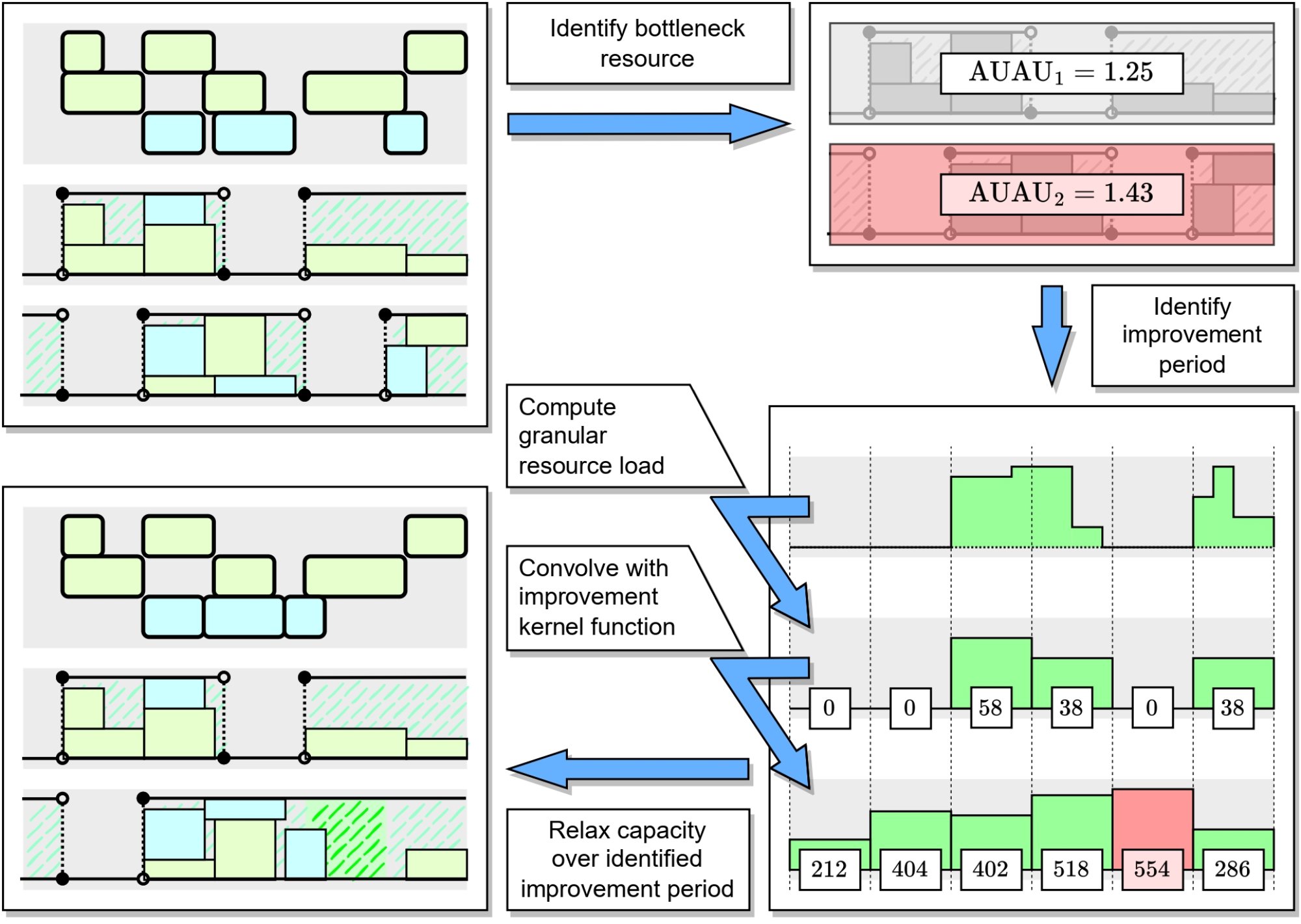
Animace výše
popsaného procesu: Na počátku obdržím rozvrh výroby, rozhodnu se pro
zlepšení času dokončení určité operace a identifikuji bottleneck zdroj,
který brání v dřívějším dokončení vybrané operace. V určeném úseku
pak navýším kapacity daného zdroje a získám nový rozvrh.
Odkazy:



