
Dohledávat v SISu (Studijní informační systém UK) jednotlivé souvislosti bývá občas náročné, natož když potřebujete vyhledávat napříč fakultami. Jindřich Bär, čerstvý absolvent magisterského programu Softwarové a datové inženýrství na Matfyzu, se to rozhodl změnit. V rámci firemního projektu a následně i diplomové práce vyvinul Charles Explorer, nástroj, který umožňuje vyhledávat předměty, studijní programy, publikace i zaměstnance z celé Univerzity Karlovy.
Mohl byste stručně představit svůj projekt?
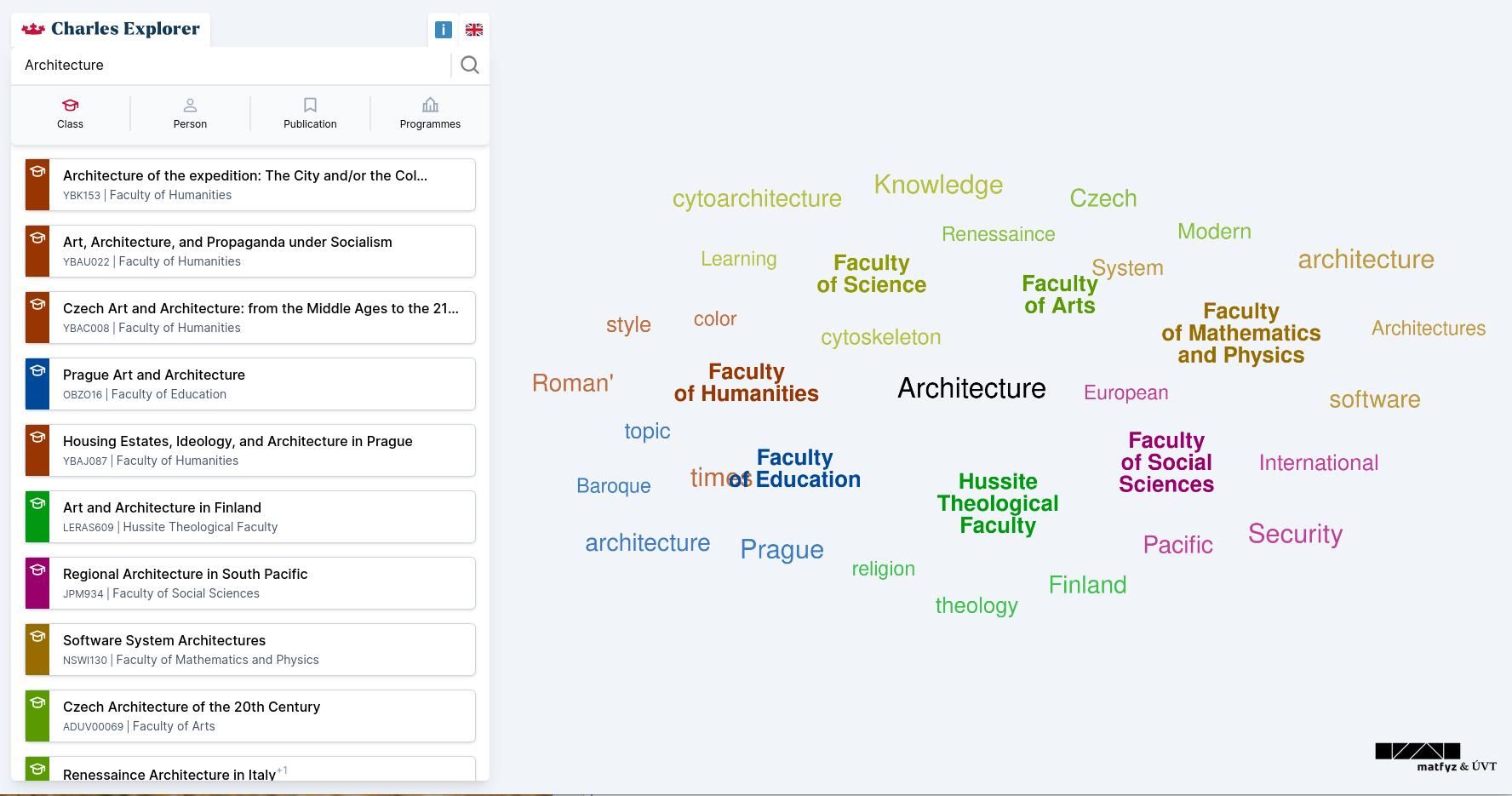
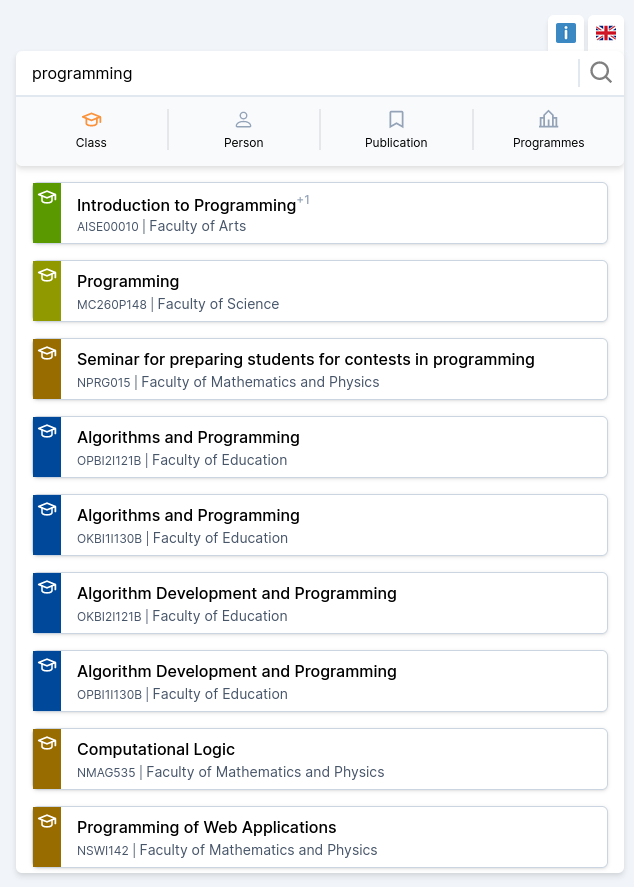
Charles Explorer je webová aplikace – vyhledávač předmětů, studijních programů, publikací a akademických pracovníků na Univerzitě Karlově. Cílím na uživatelský komfort a přehlednost, aby uživatelé mohli snadno propojovat informace napříč různými univerzitními systémy. Systém umožňuje například rychlé vyhledávání vztahů mezi akademiky a jejich publikacemi nebo předměty, které vyučují.
Co vás inspirovalo k tomu, abyste se zaměřil právě na toto téma?
V existujících systémech univerzity (SIS, Verso atp.) chyběla provázanost mezi daty – informace o publikacích a jejich autorech ve Versu, informace o předmětech v SIS, detaily o studijních programech na webových stránkách jednotlivých fakult. Profesora Skopala, vedoucího mého projektu, to inspirovalo k návrhu nástroje, který by tato data propojoval a zjednodušil jejich vyhledávání. Já jsem zároveň chtěl vytvořit platformu, která by byla intuitivnější a přístupnější pro studenty, akademické pracovníky i širší veřejnost.
Můžete vysvětlit, jaký konkrétní přínos nebo využití má vaše práce?
Oproti existujícím systémům má Charles Explorer příjemnější UX, responzivní design a umožňuje prohlížet data v souvislostech. Vztahy mezi osobami a publikacemi navíc umíme zobrazovat v grafovém („síťovém“) zobrazení, takže na data může uživatel nahlížet z různých úhlů.
Tímto snad přibližujeme univerzitu i širší veřejnosti nebo třeba uchazečům o studium, pro které mohou být stránky předmětů v SISu příliš technické. Pro každou entitu ale stále poskytujeme odkazy do stávajících systémů, abychom ještě více zlepšili provázanost dat. Tam, kde to jde, navíc data publikujeme jako Linked Data, což např. pomáhá s lepší prezentací jednotlivých entit ve webových vyhledávačích (např. Google Rich Results) a jejich dalšímu zpracování.
S jakými technologiemi jste pracoval a jaké metody jste využíval?
Node.js, PostgreSQL, Apache Solr, Memgraph a Docker. S Node.js jsem měl profesionální zkušenosti z dřívějška, zbytek stacku je dle mých průzkumů takový současný industry standard. Díky rozšířenosti těchto technologií pro ně existuje spousta integrací, podpůrných nástrojů a otázek (i odpovědí) na fórech, a tak jsem na žádném problému nestrávil příliš mnoho času.
Co pro vás bylo nejtěžší? Je něco, co byste zpětně udělal jinak?
Před využitím existujících knihoven z bodu 4 jsem asi měsíc experimentoval s vlastními implementacemi databází a full-textového vyhledávání. Toto nadělalo mnohem více škody než užitku – spoustu času jsem strávil na hledání chyb ve „své“ databázi, což zpomalilo vývoj samotné webové aplikace. Naštěstí jsem tento přístup včas opustil – někdy není potřeba objevovat Ameriku...
Jakým způsobem jste ověřoval výsledky své práce?
Pokud jde o Charles Explorer jako webovou aplikaci, měřím na něm přístupy skrze Google Analytics a Google Search Console; během vývoje jsem taky průběžně prováděl zátěžové testy a profiling webové aplikace.
V rámci diplomové práce jsem pracoval spíše s daty než se samotnou aplikací – zde jsem používal běžné metody evaluace ML modelů (cross validation, F1 skóre atp). Také jsem porovnával výsledky vyhledávání z Charles Exploreru s komerčními systémy jako Elsevier Scopus a podobnými.
Zajímavé je taky sledovat růst počtu poznámek od uživatelů – ti si občas všimnou nějaké nesrovnalosti v datech a dají nám vědět skrze e-mail.
Co považujete za nejdůležitější výsledek nebo závěr své práce?
Za klíčové považuji to, že jsme dokázali propojit různé univerzitní systémy a nabídnout uživatelům snadnější způsob, jak se dostat k relevantním informacím. Charles Explorer zjednodušuje přístup k datům, což může být užitečné pro studenty, akademické pracovníky i širší veřejnost.
Myslím si, že to přináší určitou přidanou hodnotu, hlavně co se týče lepší orientace v datech a uživatelské přívětivosti. Mimo to Explorer také vytváří platformu pro další potenciální nástroje pro průzkum univerzitních dat.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Myslím, že projekt může ukázat, jakým způsobem lze různá univerzitní data efektivně propojit a zpřístupnit uživatelům. Nemusí být nutně inspirací, ale doufám, že někomu může ukázat, jak se dá podobná problematika řešit, a možná poslouží jako dobrý základ nebo východisko pro další projekty. Každý projekt je unikátní, ale pokud někomu moje zkušenosti pomohou, budu za to rád.
Jaké jsou vaše plány do budoucna?
Zkušenosti s projektem si velmi cením, nejen že mě osobně posunula, ale také rozšířila mé portfolio. Projekt samozřejmě plánuji udržovat, dokud se neobjeví vhodný nástupce. Ačkoliv byla práce s daty zajímavá výzva, plánuji si teď dát od této oblasti menší pauzu. Rád bych se věnoval svým menším hobby projektům, ale nevylučuji, že se k datovým systémům vrátím, pokud mě osloví nějaký zajímavý projekt nebo příležitost.

Odkaz na práci: https://explorer.cuni.cz/
- zdrojový kód (https://gitlab.mff.cuni.cz/barj/charles-explorer)
- dokumentace (https://jindrich.bar/charles-explorer-docs/)



