
Strojový překlad (machine translation, MT) je přitažlivou úlohou na pomezí informatiky a lingvistiky. Zajímavý je komerčně i akademicky. Jen v Evropské unii by mohl uspořit nemalou část z miliardy EUR každoročně vydávané na překlady a tlumočení. Pro akademiky představuje hřiště řady oborů.

Kromě zmíněné lingvistiky je překlad výzvou pro statistiky, informatiky i ryzí softwarové inženýry. Dnešní praxi lze totiž shrnout takto: vezměte texty objemem odpovídající 27 metrům anglických knih společně s jejich českými překlady. Najděte dvojice vět, které si odpovídají (bude jich cca 10 milionů), a každou vybavte větným rozborem. Novou větu překládejte hledáním kousků, které jste v těch milionech vět viděli přeložené. Dříve nesmiřitelné proudy „statistiků“ a „lingvistů“ se stále více sbližují a největší potenciál dnes mají metody smíšené.
Neopomeňme přesah MT do umělé inteligence: při překladu si lze doslova sáhnout na produkty lidské mysli a snažit se je strojově napodobit. Takovou šanci pracovat s hmatatelný mi a měřitelnými daty mnohé obory kognitivních věd stále nemají.
Přečtěte si reportáž o letošní konferenci Význam v psaném a mluveném jazyce a jeho počítačové zpracování.
Přehnaná očekávání
S prvními počítači v éře Johna von Neumanna a Alana Turinga se objevily naděje na plně automatický převod textů z jednoho jazyka do druhého. V roce 1954 mělo dle tiskové zprávy IBM chybět „tři až pět let“. Rozpor mezi těmito nadějemi a skutečnými výsledky pak na deset let zablokoval přísun prostředků do této oblasti výzkumu. Dnešní vize je opatrnější. Neočekáváme, že se podaří dosáhnout plně automatického překladu vysoké kvality bez omezení typu textů. V celé řadě situací strojový překlad však dobře slouží už dnes, a to i při nízké kvalitě (např. zpřístupnění webových stránek v řeči, kde nedokážete přečíst ani písmo) či v úzce vymezených úlohách (např. heslovité návody k výrobkům).
Frázový statistický překlad
Tzv. frázový překlad pracuje se slovy jako s nedělitelnými jednotkami. Počítač nevidí žádný vztah mezi slovy kočka a kočkou, kočka a kocour nebo dokonce kočka a micinka. Překládat je v tomto modelu možné díky obrovskému objemu vět, které již dříve přeložili lidé.
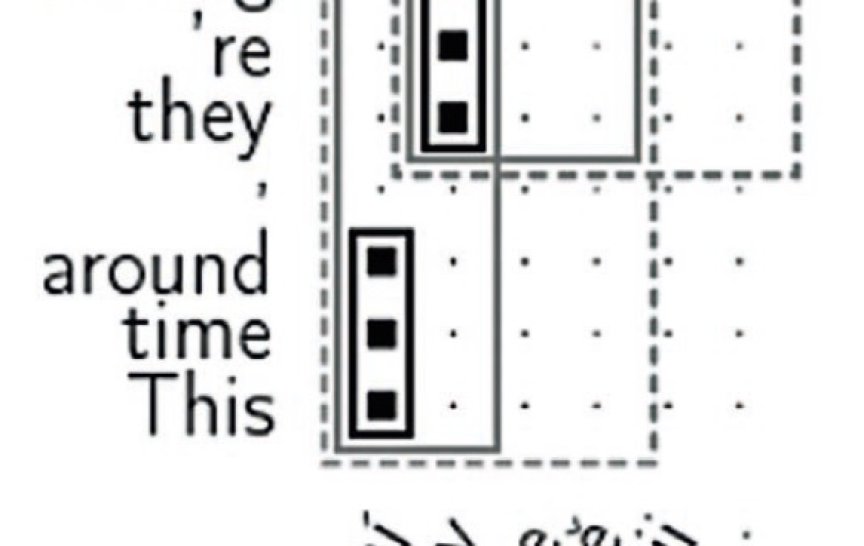
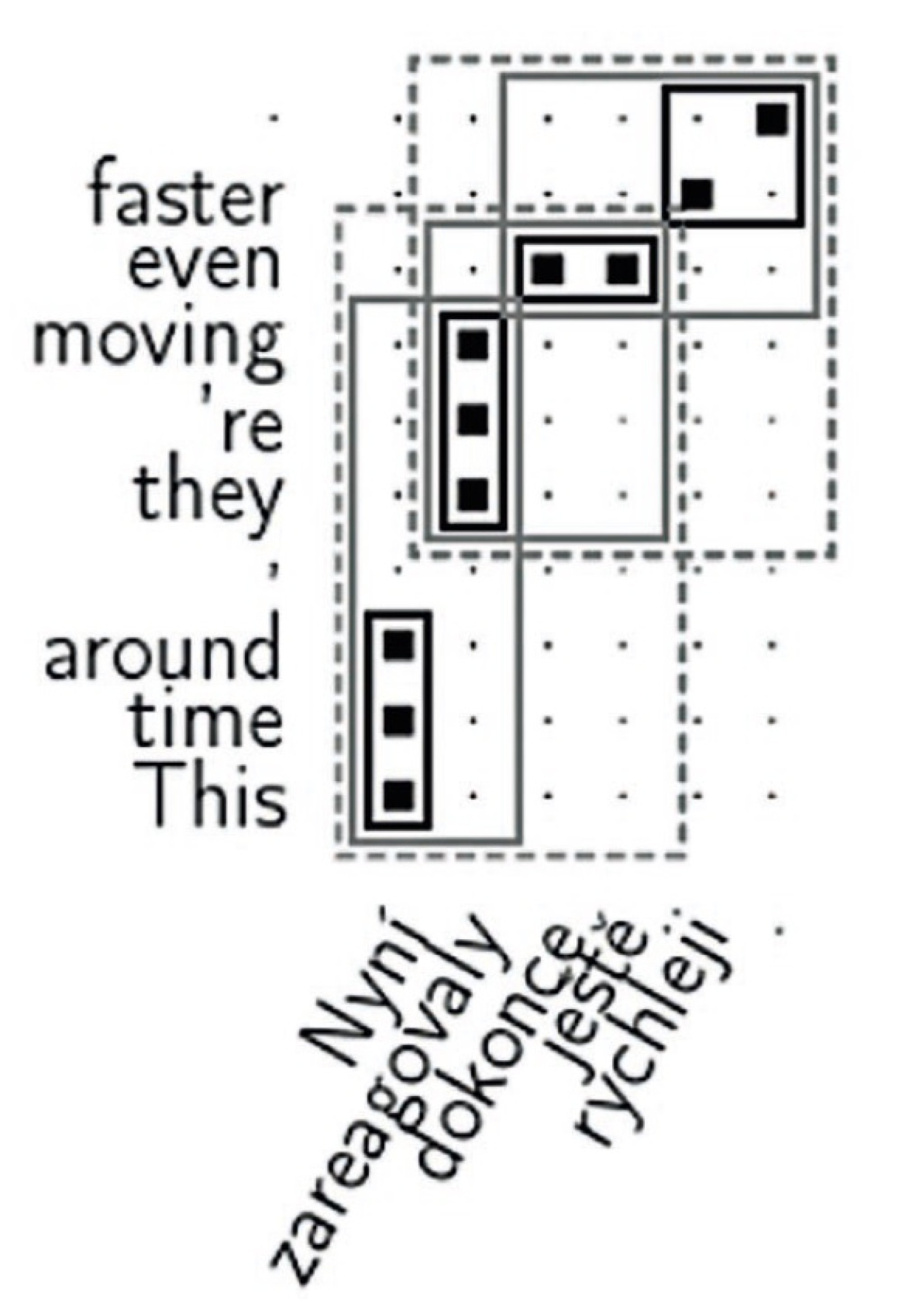
Počítač věty a jejich překlady spáruje a najde, která slova ve větě si přibližně odpovídají, viz obrázek 1. Z takto zarovnaných textů získá překladový slovník. Na rozdíl od běžných slovníků jsou v něm i desetislovné posloupnosti slov a především jsou slova uvedena ve všech tvarech, jak byla spatřena.
Po zadání vstupní věty počítač probírá varianty rozdělení věty na úseky (nelze mluvit o větných členech, úseky zcela ignorují gramatiku). Každý úsek je přeložen pomocí zmíněného slovníku. Z mnoha možností překladů úseků jsou vybrány takové, které na sebe nejlépe navazují, viz obrázek 3.
Hloubkově-syntaktický překlad
Překlad založený na větném rozboru má ambici zajistit gramatický výstup. Nepracuje se surovou podobou věty, ale převádí ji postupně na tzv. povrchovou a hloubkovou reprezentaci, jakýsi stromeček větných členů a závislostí mezi nimi.
K převodu do druhého jazyka dojde v hloubkové reprezentaci, překládá se tedy „strom na strom“, viz obrázek 2. Překladový slovník neobsahuje všechny tvary slov, stačí tvar základní. Za závěrečné skloňování a časování zodpovídá samostatná komponenta.
Systém s hloubkovým překladem sestává z mnoha součástek velmi odlišného charakteru. Pro počáteční větný rozbor se používají statistické nástroje trénované na závislostních korpusech, překladový slovník vzniká automaticky z přeložených textů. Při překladu stromu na strom je však též prostor uplatnit celou řadu stabilních lingvistických pravidel, která charakterizují rozdíly mezi zdrojovým a cílovým jazykem.